2.3 Practical Examples on AWS
2.3.1 The Data Engineering Lifecycle on AWS
Each stage of the data engineering lifecycle maps to concrete AWS services. Here is how they break down.
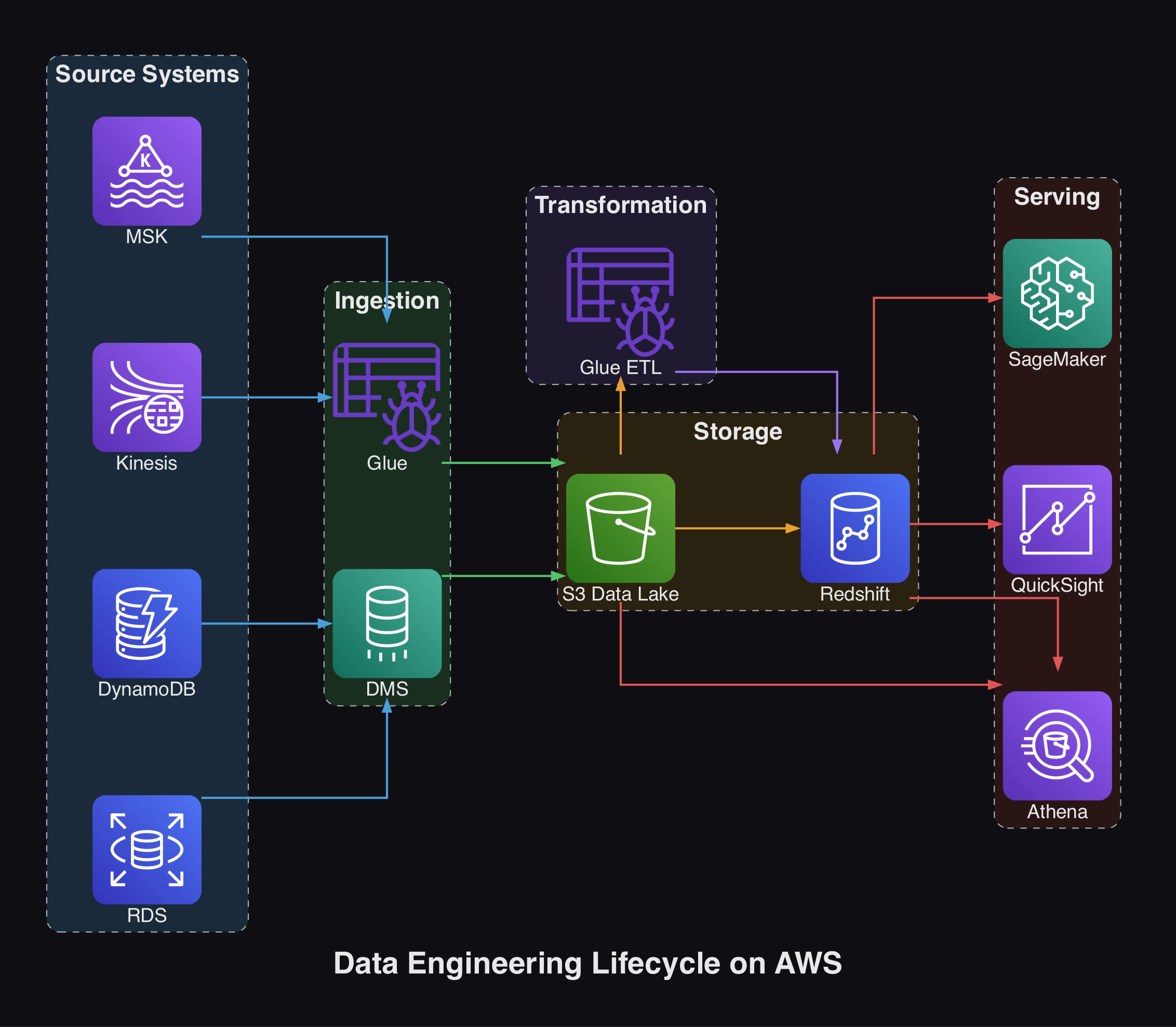
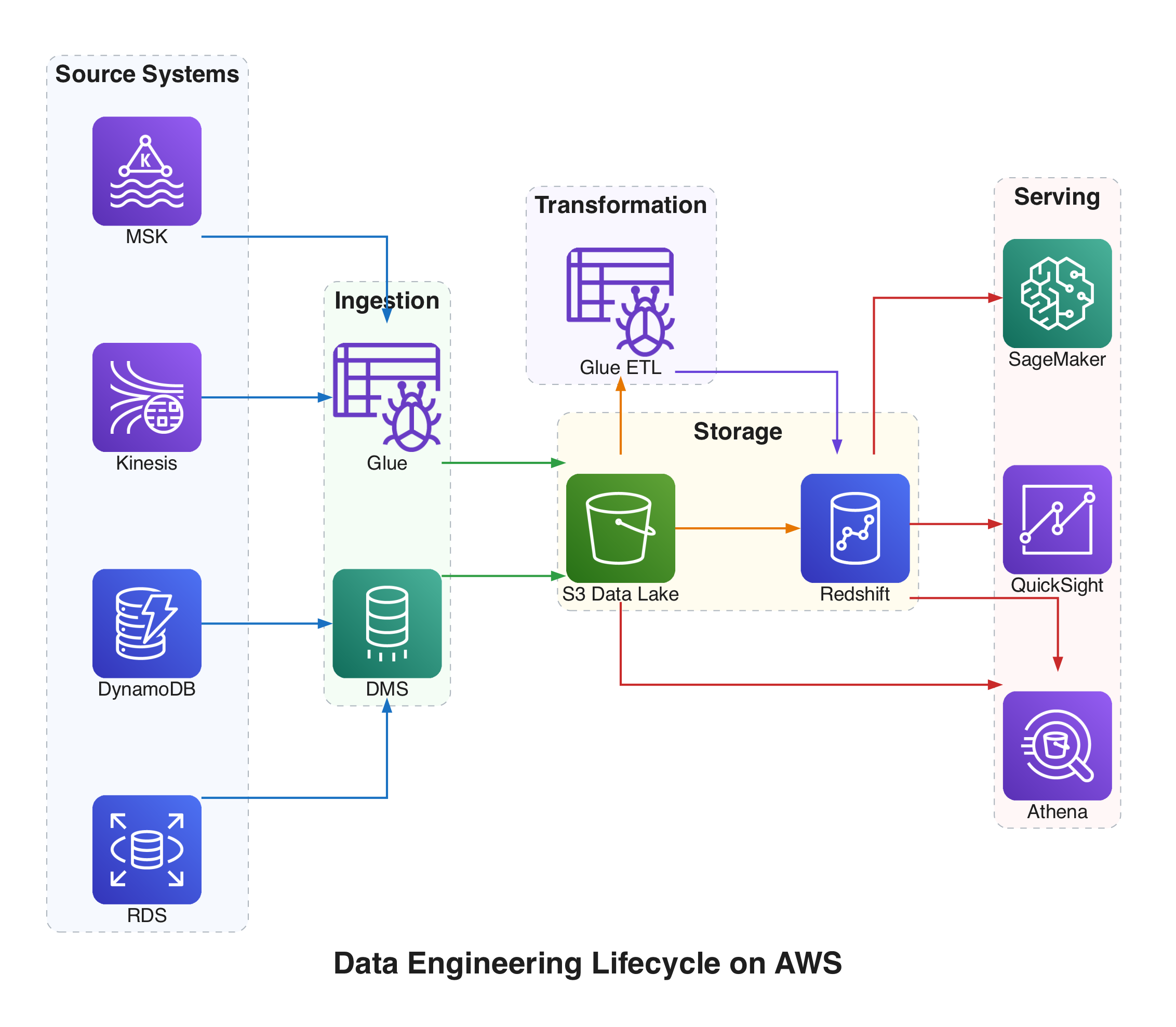
Source Systems
- Databases:
Amazon RDS- managed relational databases, reducing operational overhead.Amazon DynamoDB- serverless NoSQL with flexible schemas, best for low-latency access to large volumes of data. - Streaming Sources:
Amazon Kinesis Data Streams,Amazon SQS,Amazon MSK
Ingestion
- From a database:
AWS Database Migration Service (DMS),AWS Glue - From a streaming source:
Amazon Kinesis Data Streams,Amazon Data Firehose,Amazon SQS,Amazon MSK
Storage
Amazon Redshift- traditional cloud data warehouseAmazon S3- object storage, also the foundation for a lakehouse arrangement that can handle both structured and unstructured data
Transformation
AWS Glue,Apache Spark,dbt
Serving
- Analytics and BI: Querying with
Amazon AthenaandAmazon Redshift. Dashboarding withAmazon QuickSight,Apache Superset, orMetabase. - AI/ML: Serve batch data for model training and work with vector databases

 Amazon Kinesis
Amazon Kinesis

 AWS Glue
AWS Glue

 Amazon Redshift
Amazon Redshift

 Amazon S3
Amazon S3
2.3.2 The Undercurrents in AWS
The undercurrents also have direct AWS counterparts.
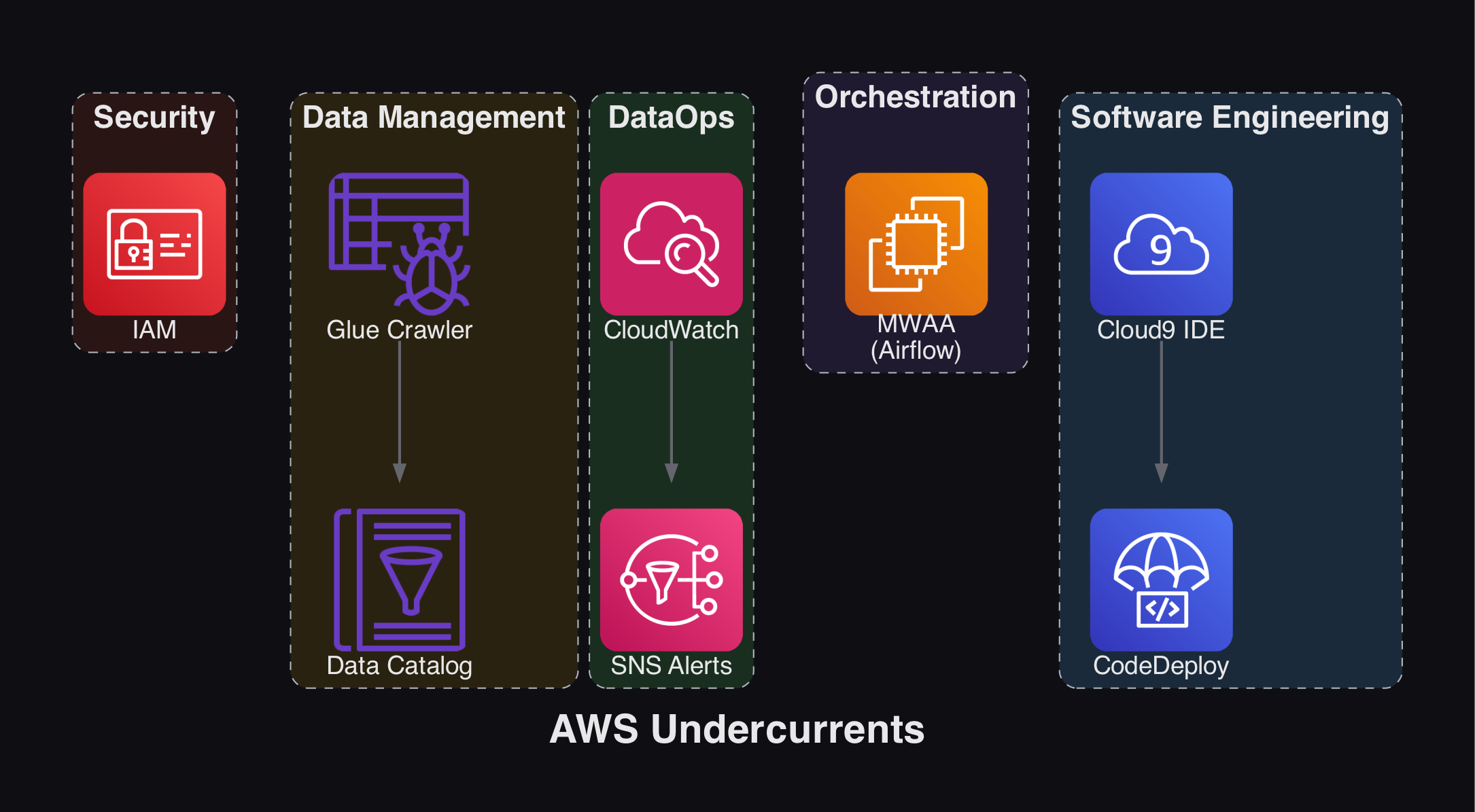
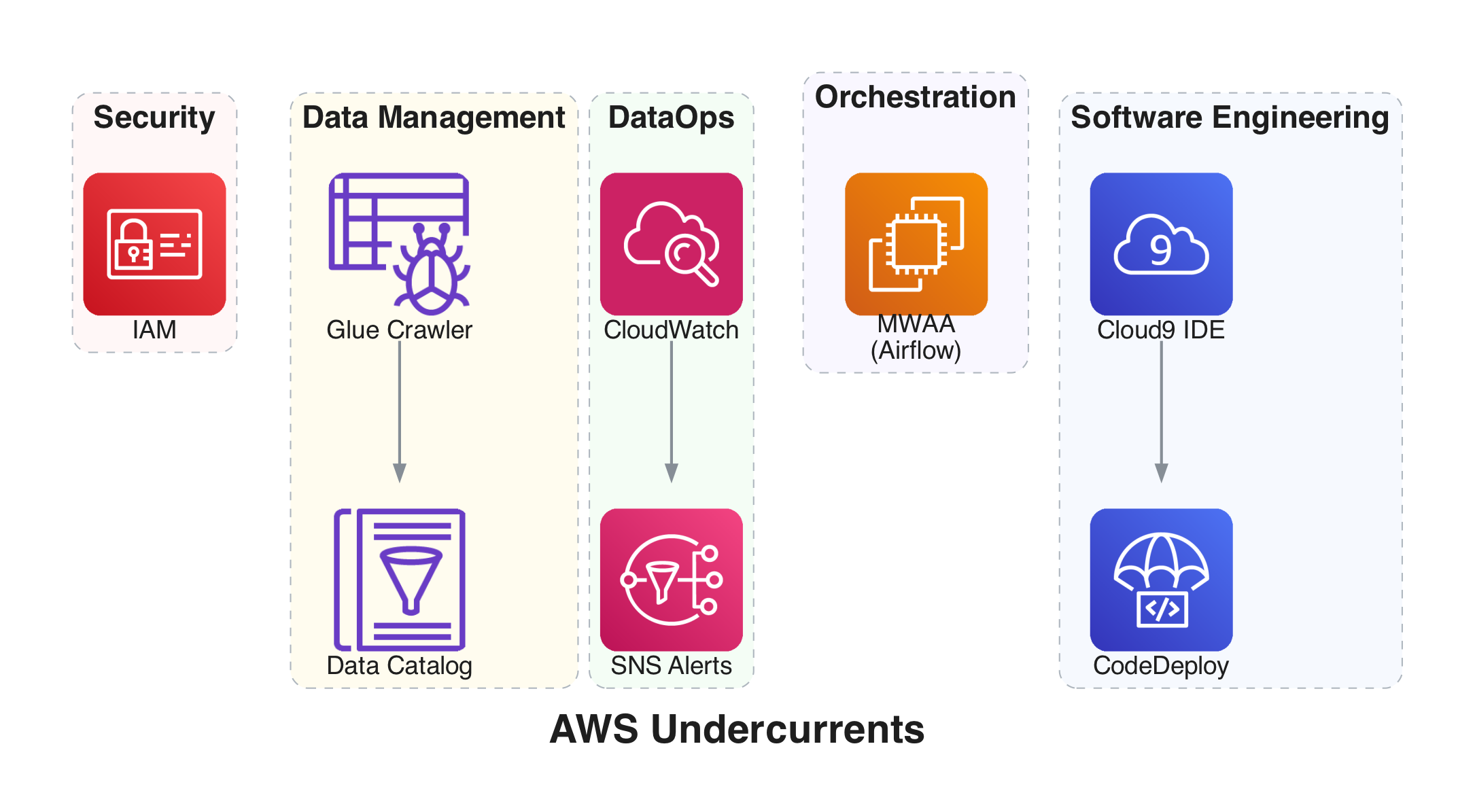
Security - AWS uses a shared responsibility model. IAM (Identity and Access Management) enforces permissions based on roles.
Data Management - AWS Glue, Glue Crawler, and Glue Data Catalog discover, create, and manage metadata for data stored across AWS storage systems.
DataOps - Amazon CloudWatch collects metrics and provides monitoring for cloud resources, applications, and on-prem systems. Amazon SNS (Simple Notification Service) handles alerting.
Orchestration - Apache Airflow remains the industry standard, available as a managed service through Amazon MWAA.
Architecture - The AWS Well-Architected Framework provides the guiding principles.
Software Engineering - AWS Cloud9 IDE (hosted on EC2) for development, AWS CodeDeploy for automated deployments, and Git/GitHub for source code management.