4.2 AWS Services for Batch Pipelines
4.2.1 AWS Services for Batch Pipelines
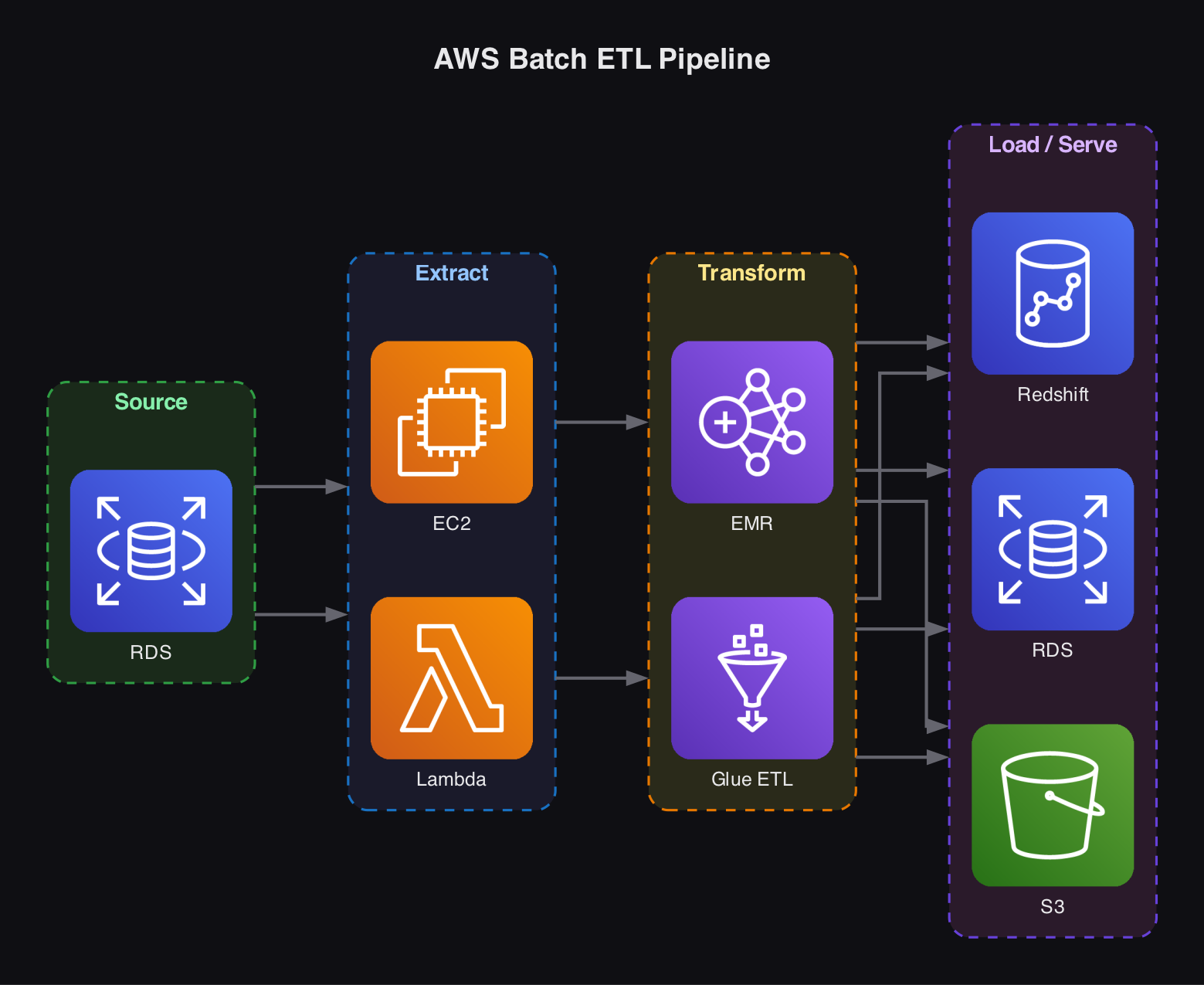
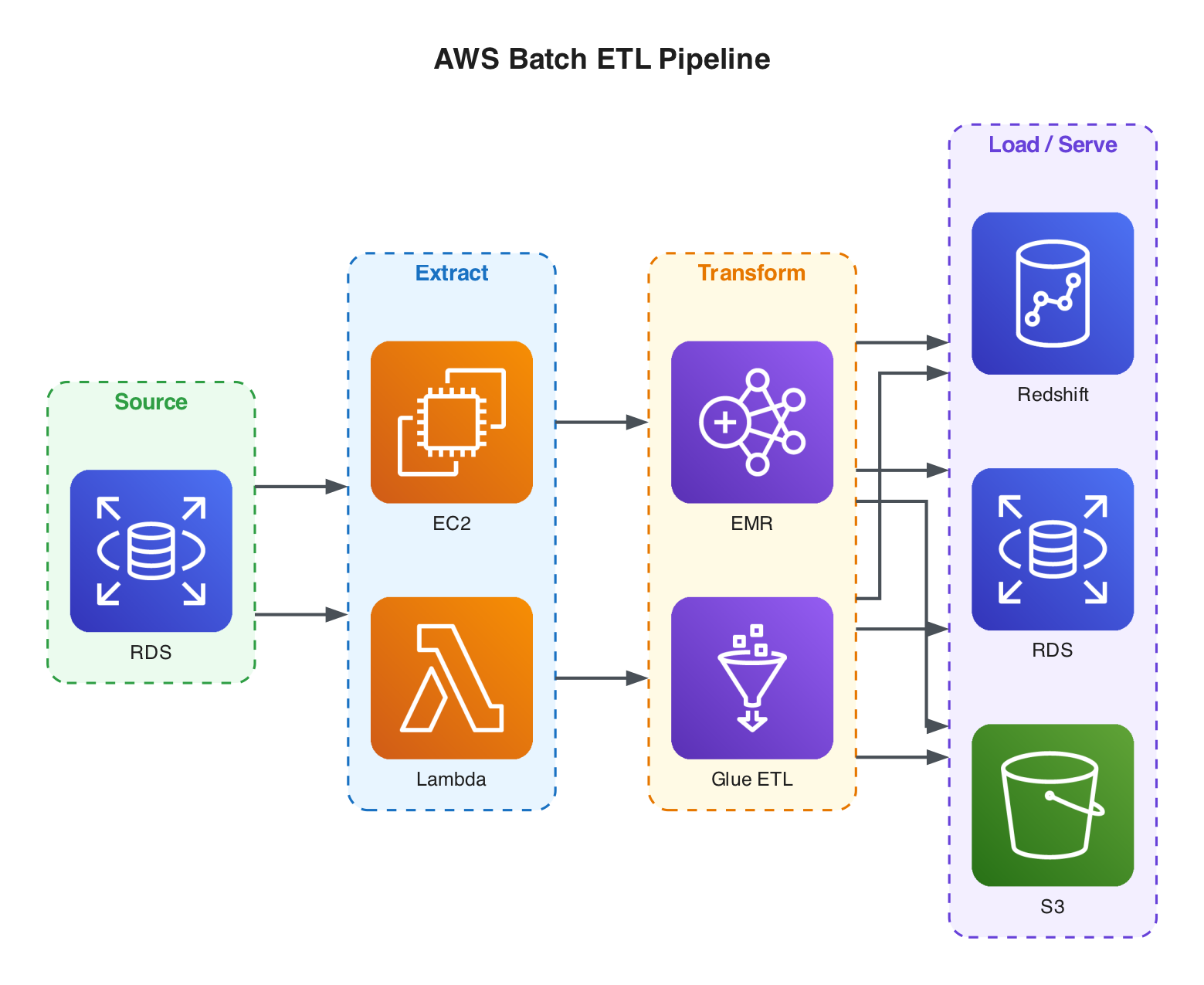
A typical batch ETL pipeline starts with a source system (e.g., Amazon RDS) and needs an extraction and transformation layer. Running this on a raw EC2 instance works but means managing software installation, security, and all the complexity of a cloud server yourself.
AWS Lambda offers a serverless alternative - you write a function to extract data from the source system with no infrastructure to manage. However, Lambda has a 15-minute timeout per invocation and limited memory and CPU, so it is best suited for lightweight tasks.
Serverless Tools for Batch Processing:
Amazon EMR- more control, designed as a big data processing toolAWS Glue ETL- more convenience;Glue Crawlerautomatically discovers and classifies data,Glue Data Catalogserves as a central metadata repository, and Glue Visual ETL lets you design pipelines graphically. A good starting point for most teams.
Load/Serve:
Where you land the processed data depends on the use case:
Amazon RDS- if normalizing tabular data using a star schemaAmazon Redshift- if running complex analytical queries on massive datasetsAmazon S3- for ML model artifacts or any workload that benefits from flexible, scalable, cost-effective object storage