2.4 AWS Data Lakehouse
2.4.1 AWS Lake Formation
AWS Lake Formation simplifies building a data lake or lakehouse by wrapping AWS Glue (ETL jobs, crawlers) and AWS IAM into a managed service that eliminates many manual setup steps.
| Capability | How it Works |
|---|---|
| Data ingestion | Integrates with Glue crawlers and ETL jobs to ingest from databases, S3, and streaming sources |
| Data catalog | Automatically discovers and catalogs datasets with schema, partition, and location metadata |
| Access control | Fine-grained permissions at the database, table, column, and row level - centralized across all consumers |
| Data sharing | Cross-account and cross-organization data sharing without copying data |
2.4.2 Implementing a Data Lakehouse on AWS
A typical AWS lakehouse implementation consists of three layers:
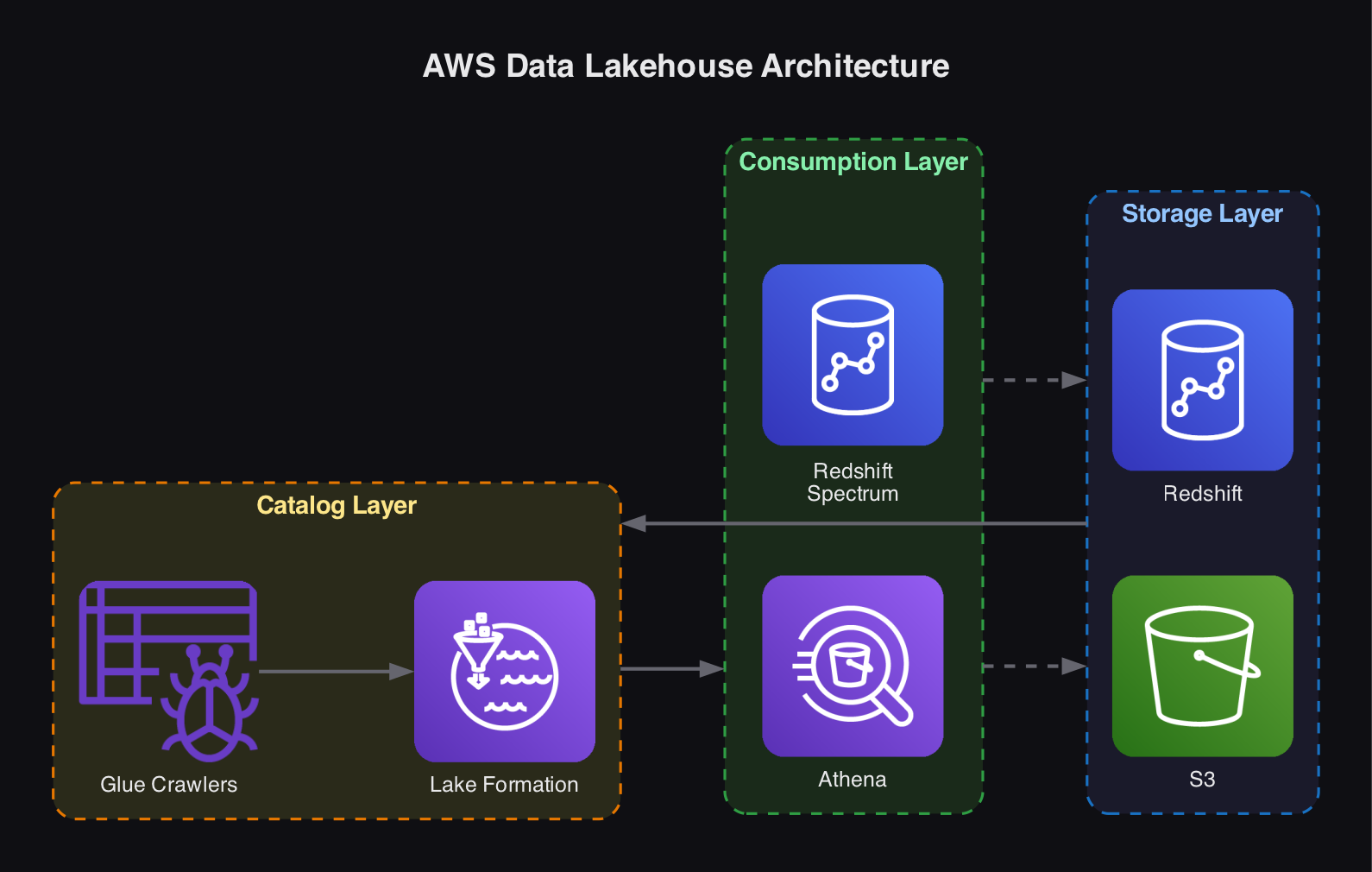
Storage Layer
| Service | Role |
|---|---|
Amazon S3 | Stores structured, semi-structured, and unstructured data in the data lake portion. Cheap, durable, and scalable. |
Amazon Redshift | Stores highly curated, structured data with a predefined schema in the warehouse portion. Optimized for complex analytical queries. |
Catalog Layer
AWS Lake Formation creates a unified data catalog using Glue crawlers that capture schema information, partition details, and data locations. Glue can periodically re-crawl the storage layer to keep metadata current as schemas, partitions, or data locations change. Apache Iceberg adds schema and data versioning on top.
Consumption Layer
| Service | Description |
|---|---|
Amazon Redshift Spectrum | Runs unified SQL queries against structured data in S3 without moving it into Redshift. Uses MPP for processing. Ideal for querying large volumes of historical data alongside hot warehouse data. |
Amazon Athena | A serverless, pay-on-demand engine that queries data in S3 using standard SQL. No infrastructure to manage. Supports federated queries across data sources including Redshift, and reads schema information from the Lake Formation catalog. |