2.1 Data Ingestion Patterns
Data ingestion is the process of acquiring raw data from various sources. This section covers different ingestion patterns, batch and streaming requirements, and key AWS tools for data ingestion.
2.1.1 Data Ingestion on a Continuum
Data ingestion isn’t a binary choice between batch and streaming — it exists on a continuum determined by how you bound your data.
Unbounded vs. Bounded Data
- Unbounded Data: Continuous stream of events (stream ingestion).
- Bounded Data: Data ingested in chunks (batch ingestion), either time-based or size-based.


2.1.2 Ways to Ingest Data
Using Connectors: JDBC/ODBC APIs that support time-based or size-based ingestion.
Using Ingestion Tools: Services like AWS Glue ETL automate regular data ingestion on a schedule.
Using APIs: Protocol-based ingestion that requires careful attention to ingestion limits per request, API call frequency, and the complexity of custom connection code tied to external documentation.
Ingesting Data from Files:
- Manual File Download
- Secure File Transfer: SFTP (Secure File Transfer Protocol) or SCP (Secure Copy Protocol)
Ingesting Data from Streaming Systems: Via Message Queues or Streaming Platforms.


Popular AWS Data Ingestion Tools
AWS Glue ETL ingests, transforms, and loads data from AWS sources (RDS, S3, Redshift). It uses Apache Spark for distributed processing and is serverless with automated scaling.
Amazon EMR is a managed cluster platform for big data processing (Hadoop, Spark). It supports large-scale transformations and ingestion and is available in serverless and provisioned modes.
AWS Glue ETL vs. Amazon EMR
| Feature | AWS Glue ETL | Amazon EMR |
|---|---|---|
| Ease of Use | Serverless, minimal setup | Requires configuration |
| Scaling | Automated scaling | Custom resource allocation |
AWS DMS (Data Migration Service) moves data between databases without transformation, supports migrations between different database engines, and is available in serverless and provisioned modes.
Other AWS Ingestion Services
- AWS Snow Family: Physical transfer appliances (Snowball, Snowcone) for large-scale migration.
- AWS Transfer Family: Secure file transfers to/from
Amazon S3using SFTP, FTP.
Third-Party Ingestion Tools: Airbyte, Matillion, Fivetran — cloud-based ETL tools.
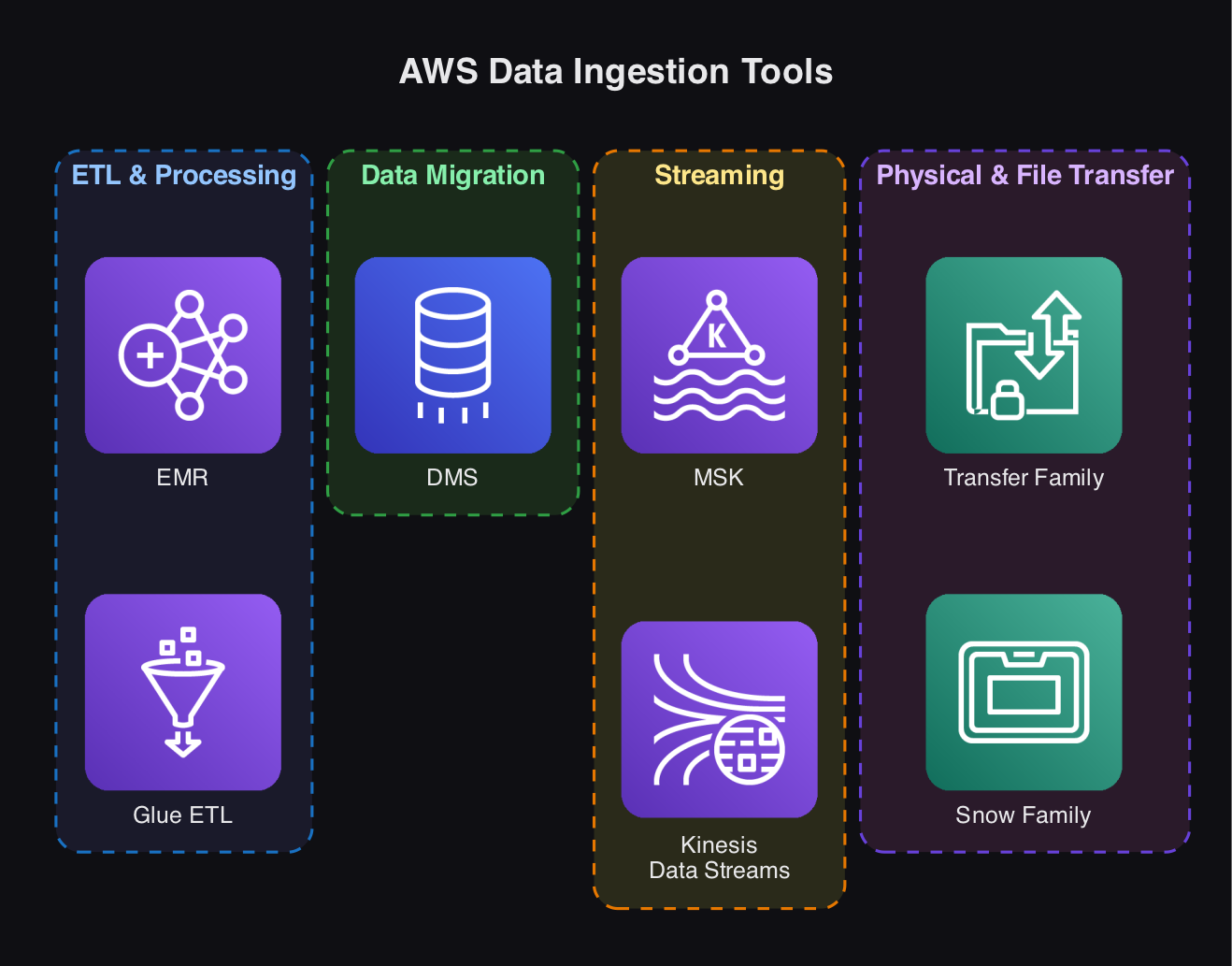
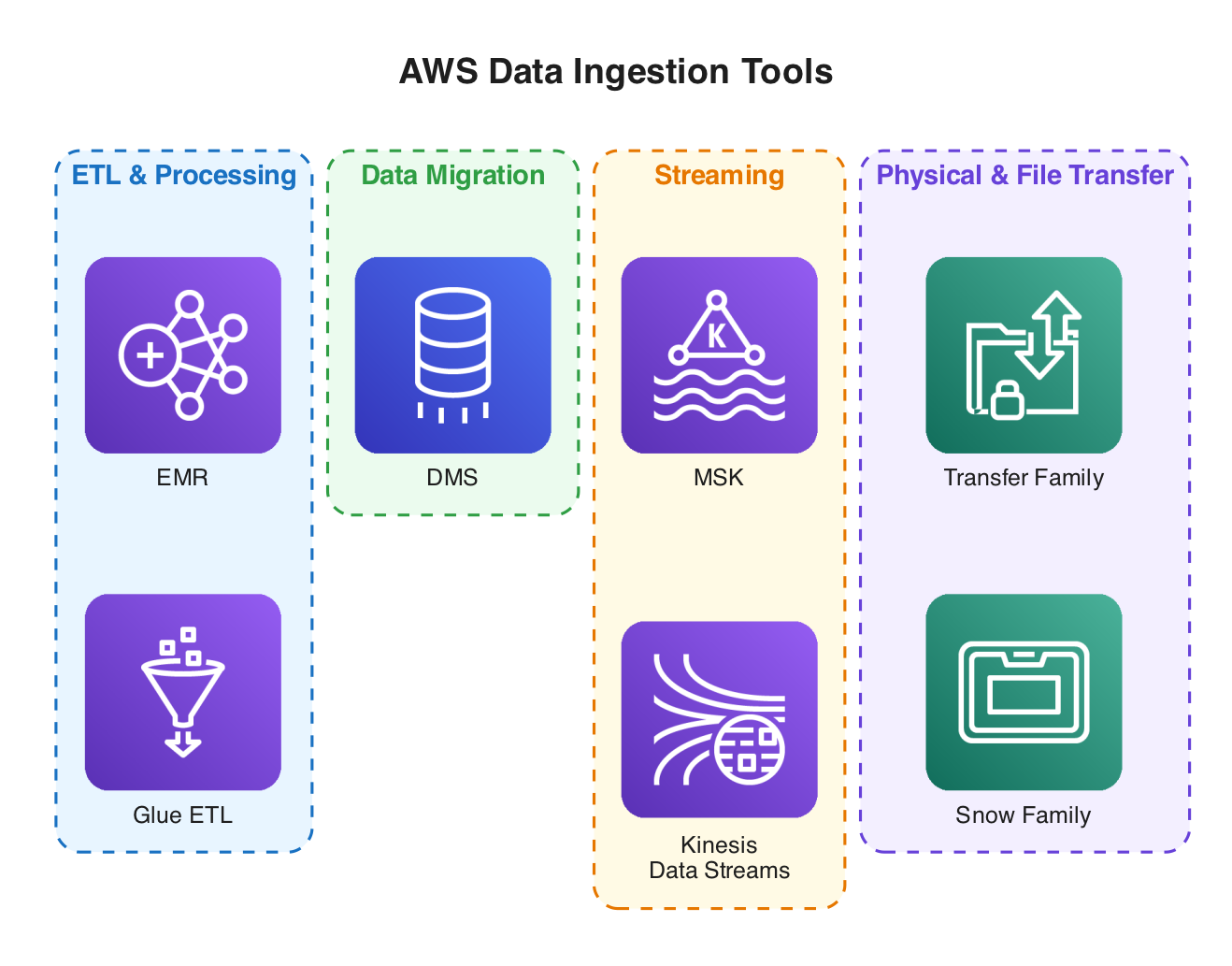
Streaming Ingestion Tools
Amazon KinesisData Streams- Amazon Managed Streaming for
Apache Kafka(MSK)
Both enable real-time data ingestion, processing, and analytics.
2.1.3 Key Considerations: Batch vs. Streaming Ingestion
Choosing between batch and streaming ingestion comes down to business value versus operational complexity.
- Use Case: Real-time ingestion is only worthwhile if it provides tangible business value.
- Machine Learning: Batch for model training; streaming for real-time predictions.
- Dashboards & Reporting: Decide between real-time and batch updates based on stakeholder needs.
- Latency: Consider millisecond updates vs. micro-batching.
- Cost: Streaming is more complex and expensive.
- System Readiness: Both source and destination systems must handle real-time data.
- Reliability & Availability: Streaming requires high availability.
Recommendation: Use real-time streaming only if the business case justifies the trade-offs.

